互联网大厂组团宕机 服务可靠性的挑战与保障之道
多家知名互联网平台接连出现服务中断或访问异常的情况,被网友戏称为“组团宕机”。从社交网络到在线支付,从云计算到音视频服务,这些事件不仅影响了亿万用户的正常使用,更将互联网服务的可靠性问题推到了风口浪尖。在数字化生活日益深入的今天,服务中断已不仅仅是技术故障,而是直接关系到社会运转与公众信任的核心问题。
服务可靠性的严峻挑战
互联网大厂的服务通常构建在极其复杂的分布式系统之上。随着微服务架构、容器化部署和混合云环境的普及,系统的复杂度呈指数级增长。一次看似简单的页面访问,背后可能涉及数百个服务的协同调用。任何一个环节的故障——无论是代码缺陷、配置错误、硬件失效,还是网络波动、依赖服务异常、甚至突发的流量洪峰——都可能像多米诺骨牌一样引发连锁反应,导致服务大面积不可用。
业务全球化带来的跨地域部署、数据合规性要求,以及应对黑灰产攻击的安全防护,都进一步增加了保障服务持续可用的难度。在追求快速迭代和业务增长的维持极高的稳定性,成为工程团队必须面对的“不可能三角”挑战。
构建韧性的系统工程
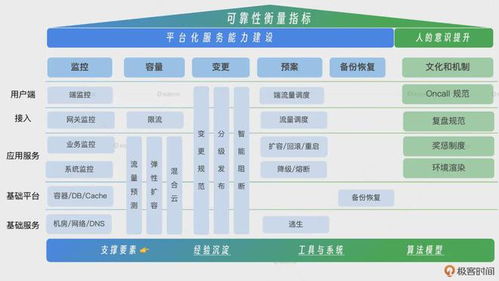
保障服务可靠性绝非一蹴而就,它需要一套贯穿设计、开发、测试、部署、运维全生命周期的系统性工程。
- 架构设计是基石:采用容错设计,如冗余部署、服务降级、熔断机制和快速故障转移。关键服务应实现多活或多区域部署,避免单点故障。系统应具备弹性伸缩能力,以应对流量波动。
- 变更管理与灰度发布:据统计,大量线上故障源于变更。必须建立严格的变更管控流程,并广泛采用蓝绿部署、金丝雀发布等灰度策略,将新版本的影响控制在最小范围,实现快速回滚。
- 全方位的监控与告警:建立覆盖基础设施、应用性能、业务指标的多维度监控体系。通过链路追踪、日志分析和智能告警,实现故障的快速发现与定位。指标应围绕服务等级目标(SLO)设定,明确可靠性承诺。
- 常态化的混沌工程:主动在生产环境中模拟故障,如随机终止实例、注入网络延迟、制造依赖服务失败等,以此验证系统的容错能力,提前发现脆弱点,将未知风险转化为已知风险。
- 高效协同的应急响应:制定详尽的应急预案并定期演练。建立清晰的线上指挥体系和跨团队协作流程,利用作战室(War Room)机制,确保在危机发生时能快速集结、信息同步、决策并执行。
文化与人:可靠性的最终防线
技术体系之上,组织文化与人的因素更为关键。
- 树立“可靠性优先”的文化:管理层需明确将服务可靠性置于与业务创新同等重要的战略高度。避免为了追求短期上线速度而牺牲稳定性的权衡。
- 推行开发者责任制(You Build It, You Run It):让开发团队对服务的全生命周期负责,能极大地提升其对代码质量和线上稳定性的主人翁意识。
- 持续复盘与知识沉淀:对每一次故障进行彻底的事后复盘(Post-mortem),不追究个人责任,而是聚焦于改进系统流程和工具,并将经验教训固化为检查清单、自动化脚本或设计规范,防止同类问题再次发生。
- 投资于工程师能力建设:通过极客时间这样的专业平台,持续为工程师提供关于高可用架构、稳定性保障、故障排查等领域的系统性学习资源,提升整个团队的技术水位。
****
互联网服务的可靠性,是技术、流程与文化的综合体。在复杂度不断攀升的数字时代,没有百分之百的不宕机承诺,只有通过持续投入和匠心运营,不断逼近“五个九”(99.999%)高可用目标的执着追求。每一次故障都是一次警醒,也是优化系统、提升韧性的宝贵机会。唯有将可靠性内化为组织的核心基因,才能在瞬息万变的环境中,赢得用户长久的信任。
如若转载,请注明出处:http://www.lnjzfp.com/product/46.html
更新时间:2026-06-19 10:09:28